Thoughts on Mapping SNN to NH(2)
希尔伯特曲线演示:
希尔伯特3D曲线演示: 3D Hilbert Curves演示。
- 之前更关注怎么优化对神经元的划分
- 方法全是适用于小于5000核的映射问题
Exixting Mapping methods – Introduction & Explanation
- PACMAN:
在进行映射时,PACMAN 采用了一种简单的先到先得技术。这意味着它按照任务的到达顺序依次进行资源分配。最先到达的任务会最先被分配到可用的处理核心上,直到所有任务都被分配完毕。
- TrueNorth:
输入层(即第一个layer)集群(clusters)被放置在固定位置。(超参数)
对于第二层及其后的每一层:每个集群会计算其到前一层所有相邻集群的距离总和。
选择距离总和最小的硬件核心来放置当前层的集群。
- DFSynthesizer:
随机初始化集群位置。
计算初始吞吐量和能耗。
在每次迭代中:随机选择两个集群并交换它们的位置。重复上述过程直到满足停止条件。
重新计算吞吐量和能耗。
如果新的映射更优,则保留新映射;否则,恢复到之前的映射。
- SDFSNN:
将SNN模型转化为SDFG模型,在SDFGs的框架下进行随机映射迭代。
- SDFGs(Synchronous Data-Flow Graphs):
1. 首先生成一个拓扑矩阵T,示例如下:
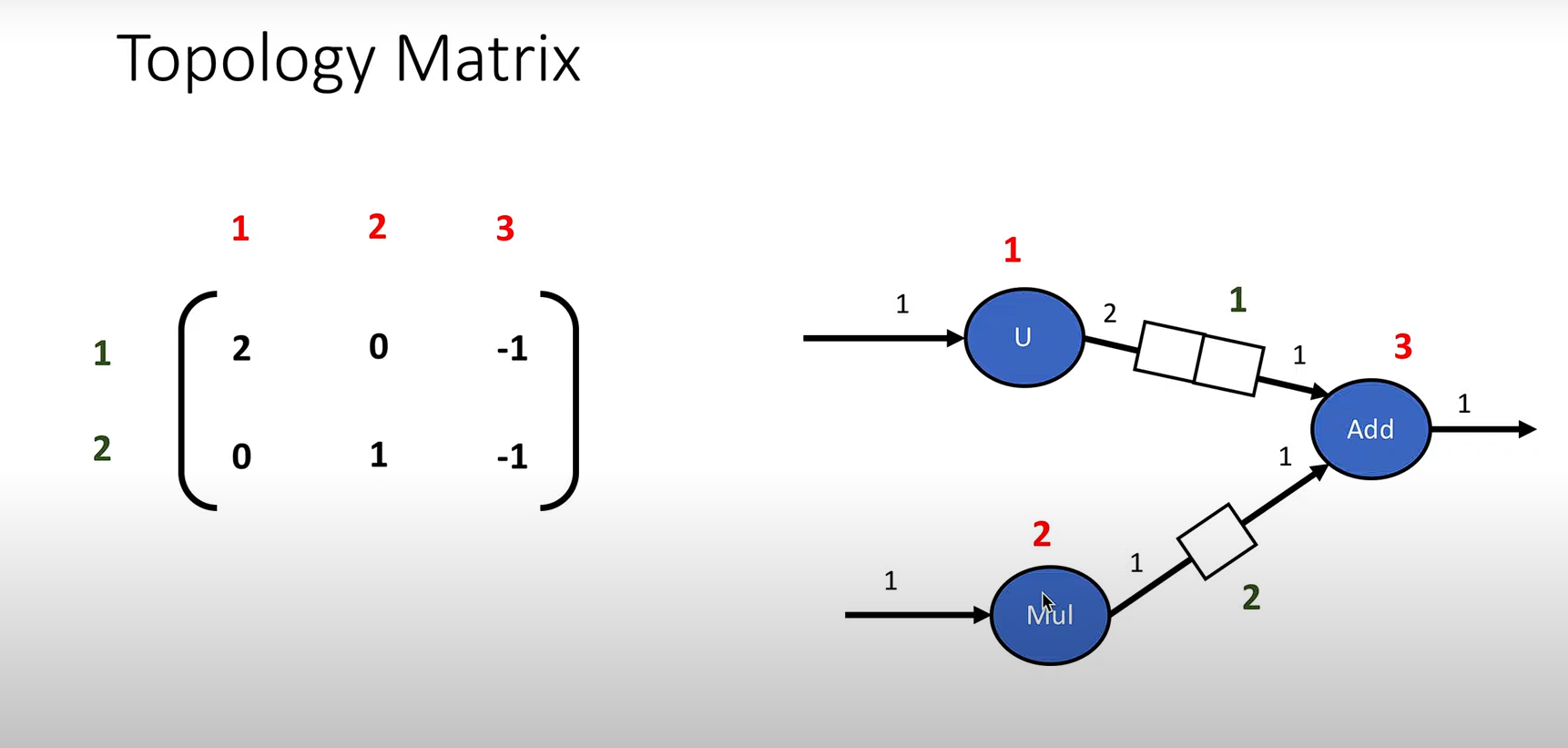
其中,红字代表节点编号,黑字代表连接节点之间有向线段的编号.而第一排第一列的意思是U点往1号线段上发送2单位信息;第二排第一列的意思是U点与2号线段无关联,无信息传输,为0;第一排第二列的意思是Add点接收1号线段上1单位信息流入. -
2. 寻找合适的Fire Vector序列, Fire Vector是指发送信号(开火)的 node,在图中的Fire Vector sequence可以表示为:
$$ \begin{bmatrix} v_1 \\ v_2 \\ v_3 \end{bmatrix} $$
v1 指的是 U(图中标明了是 1 号),vT2 指的是 Mul,以此类推。现在要找一个序列,使得 $$ T \cdot v = \begin{bmatrix} t_{11} & t_{12} & t_{13} \\ t_{21} & t_{22} & t_{23} \\ t_{31} & t_{32} & t_{33} \end{bmatrix} \cdot \begin{bmatrix} v_1 \\ v_2 \\ v_3 \end{bmatrix} $$ - 3. 之后,随机选取一个点开始,fire it, then repeat until the sequence is finished.
- SDFGs(Synchronous Data-Flow Graphs):
5. 基于SDFSNN的PSOPART:
-
初始化:
- 随机初始化粒子群,粒子数量通常在 20-100 之间
- 每个粒子代表一种可能的映射方案
- 随机初始化各粒子的位置
-
迭代过程:
-
对于每一次迭代:
-
a. 更新粒子:
- 对每个粒子执行以下操作:
-
i. 计算粒子速度和位置:
V_new = ω * V_current + c1 * rand() * (pbest - X_current) + c2 * rand() * (gbest - X_current)
Then:
X_new = X_current + V_new - ii. 更新粒子的位置
- iii. 计算新位置的适应度
-
b. 更新最佳值:
- 如果新位置适应度优于粒子的历史最佳位置 (pbest),更新 pbest.
- 如果新位置适应度优于全局最佳位置 (gbest),更新 gbest.
-
a. 更新粒子:
-
对于每一次迭代:
-
终止条件:
- 达到最大迭代次数
- 适应度改进不足
-
输出结果:
- gbest 作为查找点的结果
Queued Question
- Q: 为何不share一根线,比如c0->c2要经过c1,那么是否可以借用c0->c1的线再到c2?反正c0也要经过c1。
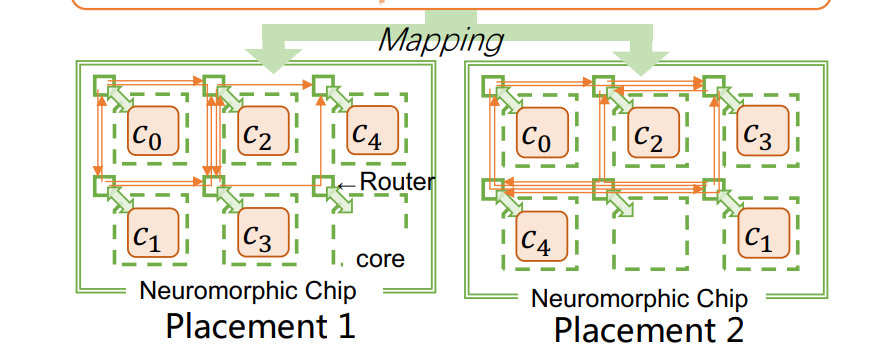
A:
1.带宽限制:每条通信线路的带宽是有限的。如果将多个通信需求共享同一条线路,可能会导致带宽不足,进而影响数据传输的速度和效率。这在高频率的神经网络通信中尤为重要。
2.数据冲突:共享线路可能会导致数据冲突,特别是在多个数据包同时需要通过同一线路时。为了避免冲突,需要复杂的调度机制,这会增加系统的复杂性和延迟。
3.通信延迟:在多跳通信(如c0->c1->c2)中,每一跳都会增加一定的延迟。如果共享线路,会使得路径上的每一跳都变得更加拥堵,从而增加整体通信延迟。
4.网络拓扑结构:神经形态硬件通常采用特定的网络拓扑结构(如2D-mesh或环网)来实现各节点之间的通信。每个节点的连接是根据这种拓扑结构预先设计好的,动态改变线路或共享线路可能会破坏这种结构,从而影响网络的性能和稳定性。
5.资源利用率:共享线路可能会导致部分线路的资源利用率过高,而其他线路资源利用率过低。为了实现高效的硬件资源利用率,通常需要对通信路径进行均衡分配,而不是让某些线路承载过多的通信任务。
6.编程和管理复杂性:管理和调度共享线路需要复杂的控制逻辑,这不仅增加了编程难度,还可能引入更多的管理开销和潜在的错误。
Ordered – Unordered – Unordered
- ordered item
- ordered item
- unordered
- unordered
- unordered item
- unordered item
- ordered item
- ordered item
Unordered – Ordered – Unordered
- unordered item
- unordered item
- ordered
- ordered
- unordered item
- unordered item
- unordered item
- unordered item
Unordered – Unordered – Ordered
- unordered item
- unordered item
- unordered
- unordered
- ordered item
- ordered item
- unordered item
- unordered item